
Introducing More Intelligent & Generative AI’s Path to Enterprise Adoption

Big news — Startupon is now More Intelligent!
Since joining Work-Bench as an investor last year, I’ve spent most of my time researching emerging technology trends and speaking with founders about what they’re building, and less time diving into which companies ambitious practitioners should join.
Given my background as a Machine Learning Product Manager at Hyperscience, I’ve been most interested in diving deeper into Artificial Intelligence and Machine Learning applications, and infrastructure.
So what’s next for More Intelligent? Moving forward, I'll be capturing my conversations with those building in the space, my independent research, and observations in this newsletter, all to help you become More Intelligent.
Check out my first More Intelligent post below:
Over the past year, we’ve seen the hype cycle of Generative AI takeover. For many founders, Large Language Models (LLMs) have removed the barrier to experimenting with ML workflows, making it easier than ever to hack together a prototype and get started. While it’s easier to get started, creating an enterprise product that satisfies the end user’s success criteria and one that is uniquely positioned relative to the immense competition that has recently emerged in this wave of the AI gold rush remains a challenge.
In terms of the enterprise applicability and productization of these models, it's been anything but straightforward. On one hand, the sector’s already raised over $15B in venture capital, and on the other, the enterprise appetite for the technology can be categorized as “cautiously optimistic”. In a recent Morgan Stanley report from 2Q’23, it was cited that only 4% of enterprises have meaningfully started to deploy capital and time to projects with significant impact.
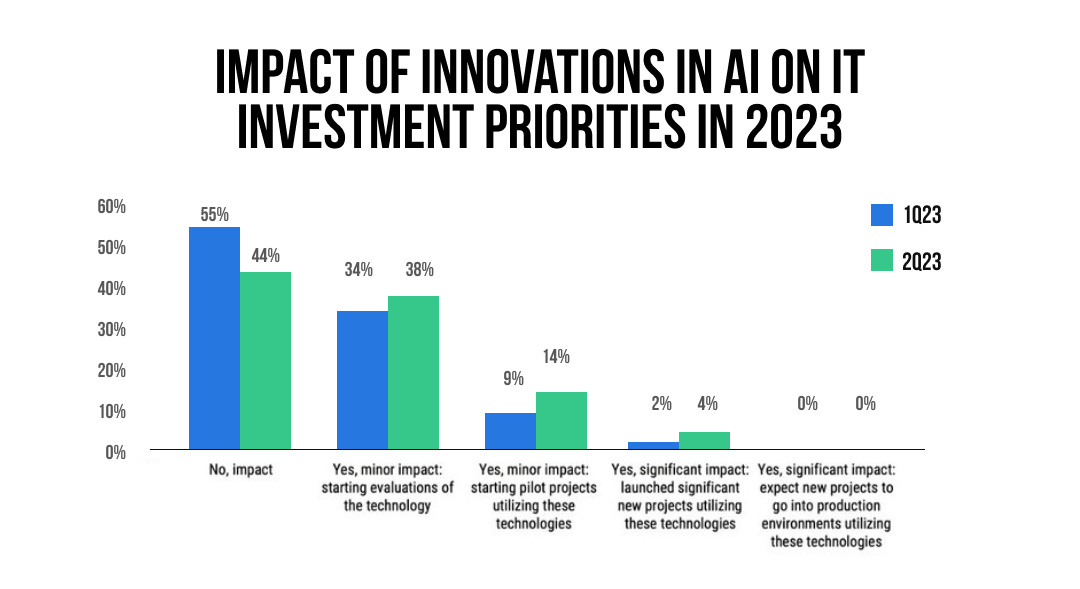
As a result, many enterprise players have found themselves in a waiting game — buyers are inundated with pitches from vendors touting the magical capabilities of LLMs, practitioners anxiously await the greenlight to start using these tools, all while procurement tries to make sense of LLM technology. We’ve even heard that procurement teams at some enterprises have paused all vendor conversations that have anything to do with LLMs.
However, the next couple of years are predicted to be a turning point for generative AI adoption – 59% of enterprises expect to increase AI/ML spending in the next 6 months and 79% expect to deploy generative AI/LLMs in the next 12 months.
Biggest Blocker to Adoption: Security, Risk & Accuracy
While the enterprise community is still getting their footing in generative AI, we dug in to better understand the limiting factors to widespread enterprise adoption and how institutions are thinking about the technology:
Sharing sensitive or proprietary data with 3rd party model providers is an additional security risk
Many enterprises feel that the bidirectional data flow associated with using vendor-built applications that leverage models from OpenAI, Cohere, Anthropic, and more represents a security risk as organizations cannot gate the data inflows and outflows during inference. Given that even the smallest errors in workflow can cost enterprises significant dollars and brand equity, depending on the type of use case and gravity of data being shared, this can be a non-starter for vendors hoping to sell enterprise-grade contracts by merely being a user interface on top of a third party LLM.
Model provider lock in creates potential to miss out on best in class models
For companies aiming to build LLM-native applications internally, being beholden to a single model provider can prove to be an inefficient way to scale as organizations will need to take a hybrid approach to provisioning access to which business units get access to LLMs let alone which LLMs they’ll allow practitioners to build with. As a result, this puts organizations in a difficult position as executives will have to determine if the cost of hosting LLMs and navigating the GPU-land is worth the squeeze.
Risk of model hallucinations make it challenging to leverage LLMs in production for high value use cases
Across both build and buy scenarios, using LLMs might not be the best fit for high-priority use cases. The fear of incorrect inferences has been noted as a limiting factor in where enterprises are willing to accept risk for new technology.
What Does The Landscape Look Like Today?
Despite these security concerns, there’s been tons of excitement from generative AI founders and investors to capitalize on the opportunity set ahead.
While the potential for LLMs is very real, many early movers have already built out the majority of the low hanging fruit use cases across the infrastructure and application layers, potentially putting the cart before the horse. This has resulted in a variety of new entrants building look-a-like products, indiscernible from one another. To add fuel to the fire, many of these companies are competing squarely against incumbents and growth-stage companies with the same technologies, as well as more brand equity and distribution channels.

Along this roller coaster ride, we’ve seen the rise and stagnation of many application layer companies leveraging commodity LLMs as their core feature, while a myriad of thin infrastructure tools sought to become the go-to picks and shovels play for an industry that is potentially advancing too fast for its own good.
How to Best Position Yourself for Enterprise Adoption
Through our conversations with enterprise practitioners, we’ve identified:
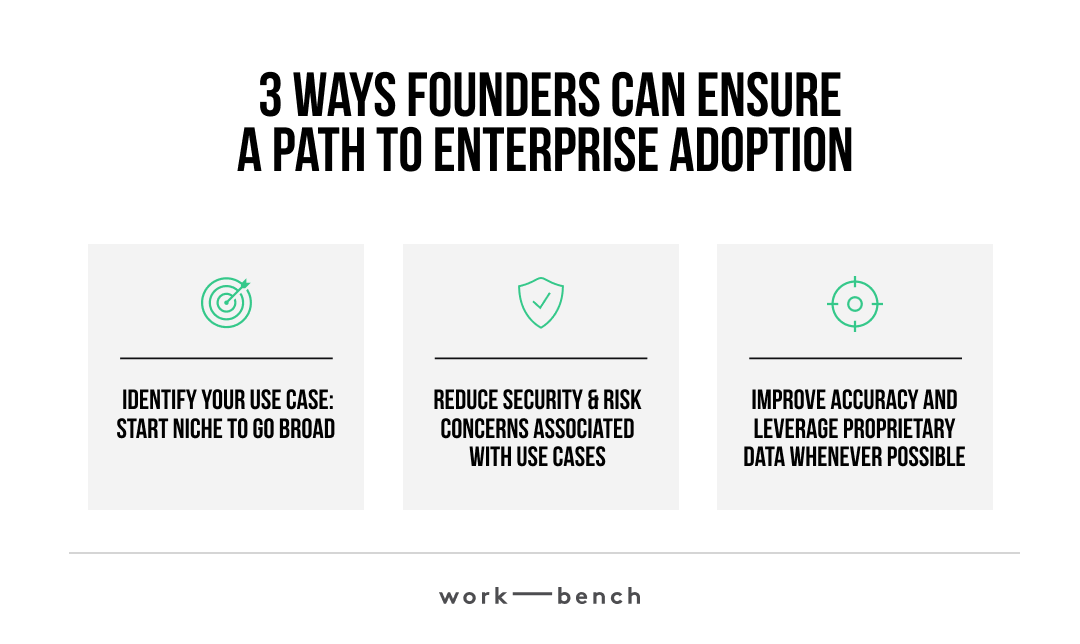
Identify Your Use Case: Start Niche To Go Broad
Oftentimes, going broad from the get-go can mean sacrificing depth in a product. When exploring which use cases are best fits for LLMs, the same sentiment applies.
As every application has (or will soon have) some flavor of AI sprinkled in, to differentiate from the pack, founders need to build in hyper-niche areas, outside of the obvious workflows. To drill into this, they should identify the atomic unit of a business process and pinpoint areas that can be improved with LLMs and focus on “speed to pain point resolution”.
A few companies building differentiated workflows:
Viso Trust*: AI-powered third party risk platform that eliminates the need for manual assessments with end-to-end automated due diligence, simplifying third party risk management to just a matter of minutes.
Tennis Finance: AI platform that empowers Fintechs to create and track compliant marketing and communications.
Bit Builder: Asynchronously generates code outside of the IDE to be used for tedious work like fixing bugs, refactoring, and addressing feedback left during code review.
Reduce Security & Risk Concerns Associated with Use Cases
As mentioned above, security and risk concerns have been the the #1 reason stopping enterprise companies from adopting LLMs. For example, many financial service institutions that deal with highly sensitive PII within their mission-critical workflows are hesitant to adopt products that share data with third-party model providers like OpenAI and Anthropic.
To avoid this, founders need to cross-reference the use case they’re targeting, deployment options, model security requirements, and the customer’s overall risk appetite to ensure there’s a path to enterprise adoption.
Since LLMs are probabilistic models, it can be challenging to guarantee the results of running inference. Similar to the principles above, startups need to ensure that core business processes and workflows will not be compromised by hallucinations and false positives. To do this, companies need to identify user acceptance levels for hallucinations and incorporate Human in the Loop (HITL) processes to validate that LLM-generated responses are accurate and suitable for enterprise-level production workflows.
A few examples of companies helping secure LLMs in Production:
Arthur*: Tackles critical safety and performance issues in LLMs, by identifying and resolving LLM application issues before they become costly business problems.
Guardrails: Guardrails is a Python package that lets a user add structure, type and quality guarantees to the outputs of large language models (LLMs).
HoneyHive: Provides developers the tools, workflows, and visibility they need to safely deploy and continuously improve LLM-powered products.
Improve Accuracy and Leverage Proprietary Data Whenever Possible
While many of today’s best known LLM-enabled applications like Github Copilot and ChatGPT are awe inspiring, their data is more limited than meets the eye:
“Frozen in Time”: LLMs lack up-to-date information as it’s infeasible to re-train models given their massive data sets.
Lack Domain-Specific Knowledge: LLMs are trained for generalized tasks, meaning they do not know your company’s private data.
Black Boxes: Auditing inference is challenging, so understanding where results came from can be impossible.
Costly: It is expensive to train and deploy models based on proprietary data.
Unfortunately, these issues impact the accuracy of LLM-enabled applications that require advanced queries and retrieval capabilities. LLM’s limitations can be particularly dangerous for enterprise-grade workflows which can be heavily scrutinized given the severity of the business process an application may be used for.
Despite these limitations, product builders still want to leverage the power of LLMs. Instead of training a net-new model and costing an organization millions, engineers from Facebook created a way to embed proprietary data into static LLMs. RAG first came to the attention of generative AI developers after Facebook AI Research published, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” in 2020.
RAG serves as a means of fetching up-to-date or context-specific data from external databases and making it available to an LLM when asking it to generate a response. This allows engineers to build proprietary business data into applications while reducing the likelihood of hallucinations and improving inference performance. By implementing business specific data into an application, founders can further insulate themselves from competition by creating the building blocks of a data moat and help customers leverage LLMs in production by citing their sources and improve auditability of the inference.
While LLMs continue to grow in size and knowledge, they are inherently limited in their ability to access and precisely manipulate knowledge-intensive tasks, meaning their performance can lag behind task-specific architecture based models. Another option is to chain together smaller task oriented models that are less computationally intensive.
A few examples of companies helping enable proprietary data:
Unstructured: Unstructured effortlessly extracts and transforms complex data for use with every major vector database and LLM framework.
Kay.AI: Data embeddings API to enable RAG in production.
Nux.AI: Empowers non-technical users to easily run, test, version, and deploy "stages" of multimodal models in a sequential chain.
Despite the challenges listed above, we believe generative AI is still poised to have a significant impact across the enterprise. While no model is magic, generative AI does give founders a head start in building ML workflows into products. In the long-term, we see the best products as those that have identified a differentiated use case, securely deployed their product in accordance to a user’s accepted risk levels, and augmented third-party LLMs with proprietary data to improve the end user’s overall experience.
The pivotal question now is: when will that transformation happen? Over the next six months, we see the prospect of entering what Gartner terms the “Slope of Enlightenment” – a phase wherein a technology’s benefits for the enterprise start to crystallize and become more widely understood, but for now, we might just be in the “Trough of Disillusionment.”
*Work-Bench portfolio company.